






ニュース
NEC、半分の学習データで識別可能なディープラーニング技術を開発
2019/08/20 11:00




NECは、従来の半分程度の学習データ量でも高い識別精度を維持できるディープラーニング技術を開発した。
従来技術と新技術の違い
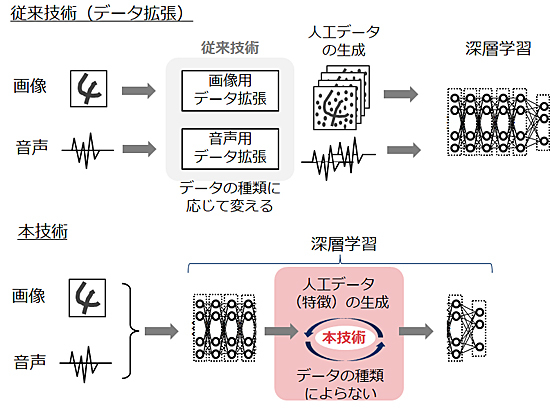
従来の技術では、識別精度を高めるために、識別が難しい学習データをより多く学習することが有効だ。新開発した技術はニューラルネットワークの中間層で得られる特徴量を意図的に変化させることで、識別が難しい学習データを集中的に人工生成する。これにより、少ない学習データ量でも識別精度を大きく向上させ、ディープラーニングを適用したシステムの開発期間短縮が可能になる。
データ拡張と呼ばれる従来技術では、ニューラルネットワークに入力する前にデータを意図的に加工・変形させ、学習データ量を人工的に増やしてきた。しかし、この増やし方では「苦手な学習データ」の量が不十分で、かつ識別精度の向上に寄与しないデータも多く生成され、十分な学習効果が得られなかった。
新技術では、ニューラルネットワークの中間層で得られる特徴量を意図的に変化させることで、識別が失敗しやすい「苦手な学習データ」を集中的に人工生成する。これにより識別精度を高める。新技術を公開データベースで評価したところ、学習データ量が半分でも従来技術と精度が変わらないことを確認した。
また、従来のデータ拡張では、データの種類ごとにデータの生成方法を変える必要があった。例えば、画像では大きさや回転角度など、音声では声の高さや話す速さなどを変えることでデータを人工的に増やしてきた。さらに、専門家がデータ生成方法を慎重に選び、学習に悪影響を及ぼすデータが発生しないよう調整する必要があった。
新技術では、ニューラルネットワーク内部の数値に基づいて自動的に学習データを生成するため、多様なデータに対して汎用的かつ効率良く適用することができる。また専門家による調整が不要だ。
従来の技術では、識別精度を高めるために、識別が難しい学習データをより多く学習することが有効だ。新開発した技術はニューラルネットワークの中間層で得られる特徴量を意図的に変化させることで、識別が難しい学習データを集中的に人工生成する。これにより、少ない学習データ量でも識別精度を大きく向上させ、ディープラーニングを適用したシステムの開発期間短縮が可能になる。
データ拡張と呼ばれる従来技術では、ニューラルネットワークに入力する前にデータを意図的に加工・変形させ、学習データ量を人工的に増やしてきた。しかし、この増やし方では「苦手な学習データ」の量が不十分で、かつ識別精度の向上に寄与しないデータも多く生成され、十分な学習効果が得られなかった。
新技術では、ニューラルネットワークの中間層で得られる特徴量を意図的に変化させることで、識別が失敗しやすい「苦手な学習データ」を集中的に人工生成する。これにより識別精度を高める。新技術を公開データベースで評価したところ、学習データ量が半分でも従来技術と精度が変わらないことを確認した。
また、従来のデータ拡張では、データの種類ごとにデータの生成方法を変える必要があった。例えば、画像では大きさや回転角度など、音声では声の高さや話す速さなどを変えることでデータを人工的に増やしてきた。さらに、専門家がデータ生成方法を慎重に選び、学習に悪影響を及ぼすデータが発生しないよう調整する必要があった。
新技術では、ニューラルネットワーク内部の数値に基づいて自動的に学習データを生成するため、多様なデータに対して汎用的かつ効率良く適用することができる。また専門家による調整が不要だ。
- 1
関連記事
NECの空飛ぶクルマの試作機は「浮く」だけ、年内には移動実験も
空飛ぶクルマの試作機が飛んだ! NECとCARTIVATORが共同で実証実験
【NECプラットフォームズ社長インタビュー】ハードウェアでしか解決できない 領域はむしろ拡大している
救急医療で生体認証活用した意思確認システム 実証データなどを規制の見直しにつなげる――NECと北原病院グループ



